如何将Word文档里面的表格批量导入到Excel里面,代码已经可以在Python里面运行并得到结果,
回复内容
https://getquicker.net/Sharedaction?code=0dac8cea-c7c3-4a2b-bec6-08ddcd652bdf
这是一个简单的py测试,向TXT文件写入内容,新建一个空白的TXT文件就行,你参考一下
涛涛涛
最后更新于 2025-07-28 19:39
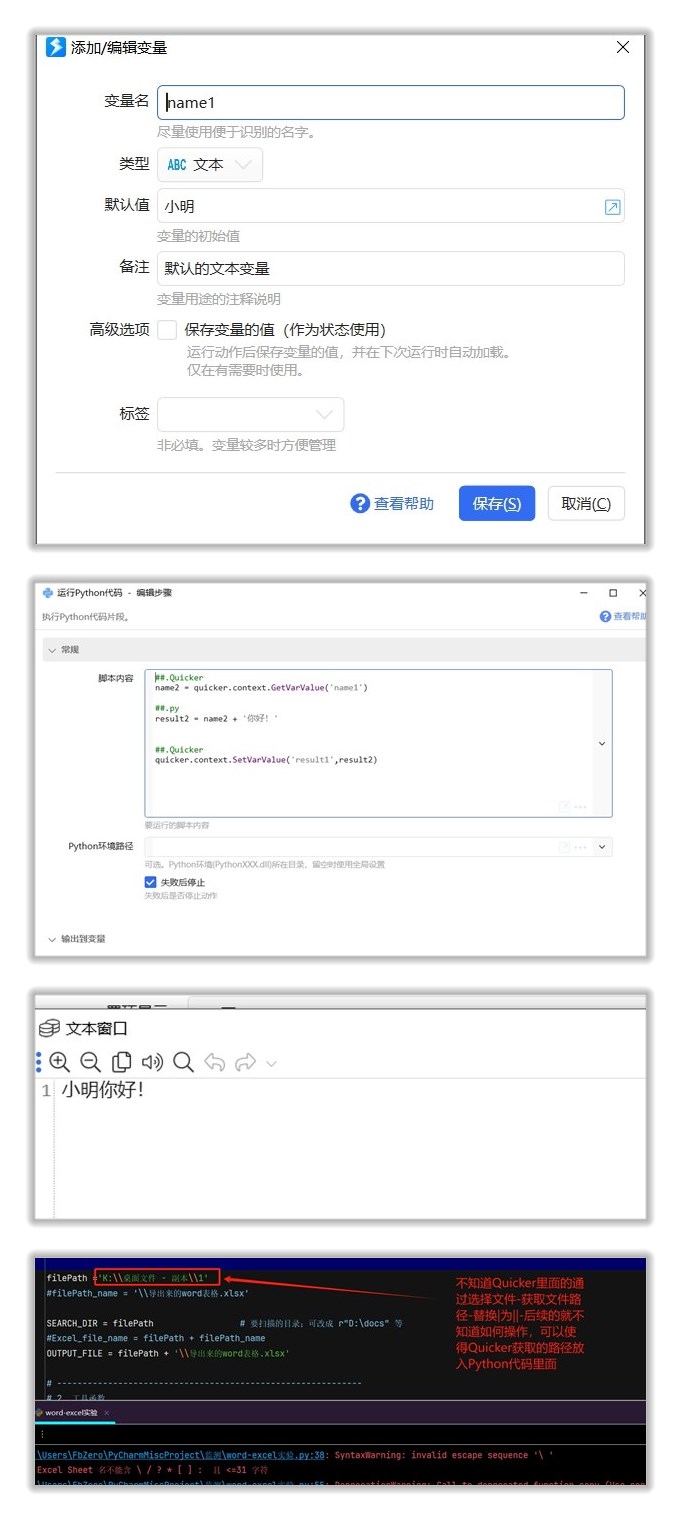
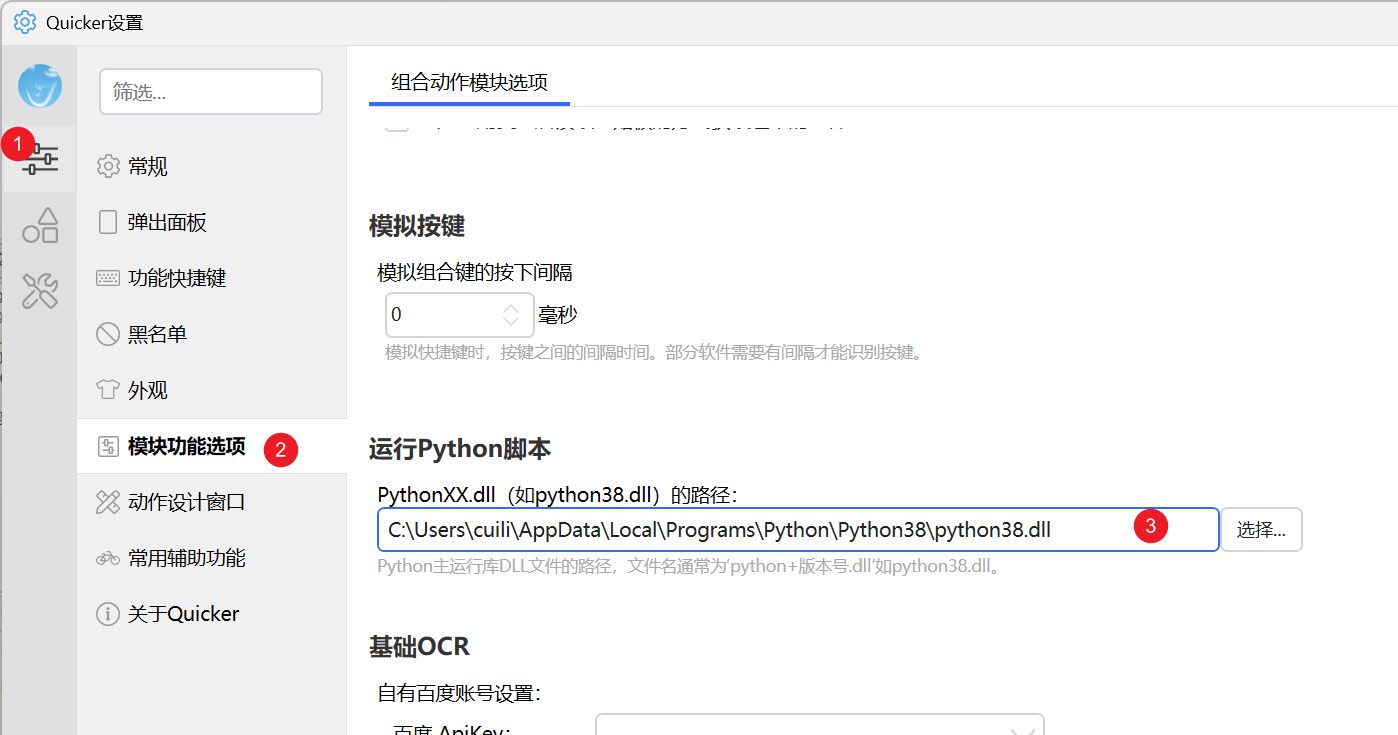
或者也可以用运行脚本,相当于执行python.exe 代码.py 。 通过文本插值把路径插值到py代码里。
输入到py好说,可以直接用文本插值 文本插值 - Quicker。 要返回给quicker,建议还是使用python模块。

 京公网安备 11010502053266号
京公网安备 11010502053266号
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
export_word_tables.py
批量把指定目录下所有 .docx 中的表格导出到单个 Excel 文件(一 Word 一 Sheet)
"""
import os
import re
from pathlib import Path
from docx import Document
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
# ------------------------------------------------------------
# 1. 配置
# ------------------------------------------------------------
'''if len(sys.argv) >= 3:
SEARCH_DIR = sys.argv[1]
OUTPUT_FILE = sys.argv[2]
'''
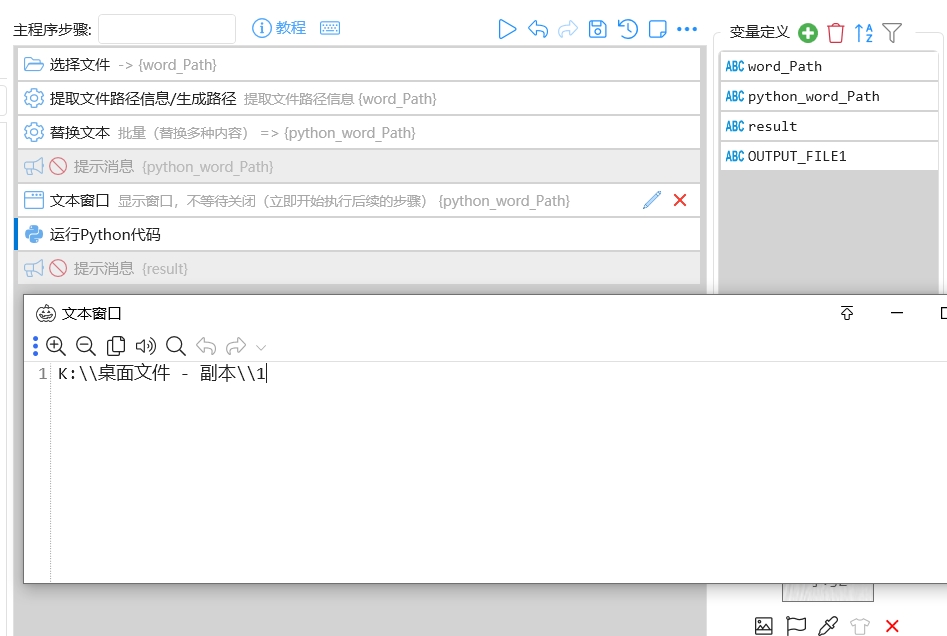
filePath ='K:\\桌面文件 - 副本\\1'
#filePath_name = '\\导出来的word表格.xlsx'
SEARCH_DIR = filePath # 要扫描的目录;可改成 r"D:\docs" 等
#Excel_file_name = filePath + filePath_name
OUTPUT_FILE = filePath + '\\导出来的word表格.xlsx'
# ------------------------------------------------------------
# 2. 工具函数
# ------------------------------------------------------------
def sanitize_sheet_name(name: str, max_len: 31) -> str:
"""
Excel Sheet 名不能含 \ / ? * [ ] : 且 <=31 字符
"""
name = re.sub(r"[\\/*?:\[\]]", "_", name)
return name[:max_len]
def docx_tables_to_sheet(doc_path: Path, ws):
"""
把一个 docx 里的所有表格写到 ws 工作表
"""
doc = Document(doc_path)
if not doc.tables:
return False # 没有表格
current_row = 1
for tbl_idx, table in enumerate(doc.tables, 1):
# 表头:表格 1、表格 2 ...
ws.cell(row=current_row, column=1, value=f"表格 {tbl_idx}")
ws.cell(row=current_row, column=1).font = ws.cell(row=1, column=1).font.copy(bold=True)
current_row += 1
# 写数据
for r, row in enumerate(table.rows, current_row):
for c, cell in enumerate(row.cells, 1):
# 合并单元格会重复,取第一个 text
text = re.sub(r"\s+", " ", cell.text).strip()
ws.cell(row=r, column=c, value=text)
current_row = r + 1 # 跳过已写行
return True
# ------------------------------------------------------------
# 3. 主流程
# ------------------------------------------------------------
def main():
wb = Workbook()
# 删除默认空 Sheet
if "Sheet" in wb.sheetnames:
std = wb["Sheet"]
wb.remove(std)
search_path = Path(SEARCH_DIR).resolve()
docx_files = search_path.rglob("*.docx")
for docx_file in docx_files:
sheet_name = sanitize_sheet_name(docx_file.stem, 31)
# 避免重名
counter = 1
original = sheet_name
while sheet_name in wb.sheetnames:
sheet_name = f"{original}_{counter}"
counter += 1
ws = wb.create_sheet(title=sheet_name)
written = docx_tables_to_sheet(docx_file, ws)
if not written:
wb.remove(ws) # 没表格就删掉空 Sheet
continue
# 自动列宽(简单版)
for col in ws.iter_cols():
max_len = max(len(str(cell.value or "")) for cell in col)
ws.column_dimensions[get_column_letter(col[0].column)].width = min(max_len + 2, 50)
if not wb.sheetnames:
print("未在任何 .docx 中发现表格,未生成文件。")
return
wb.save(OUTPUT_FILE)
print(f"完成!已生成 {OUTPUT_FILE},共 {len(wb.sheetnames)} 个 Sheet。")
# ------------------------------------------------------------
if __name__ == "__main__":
main()